准备工作
准备两张表,orders,users
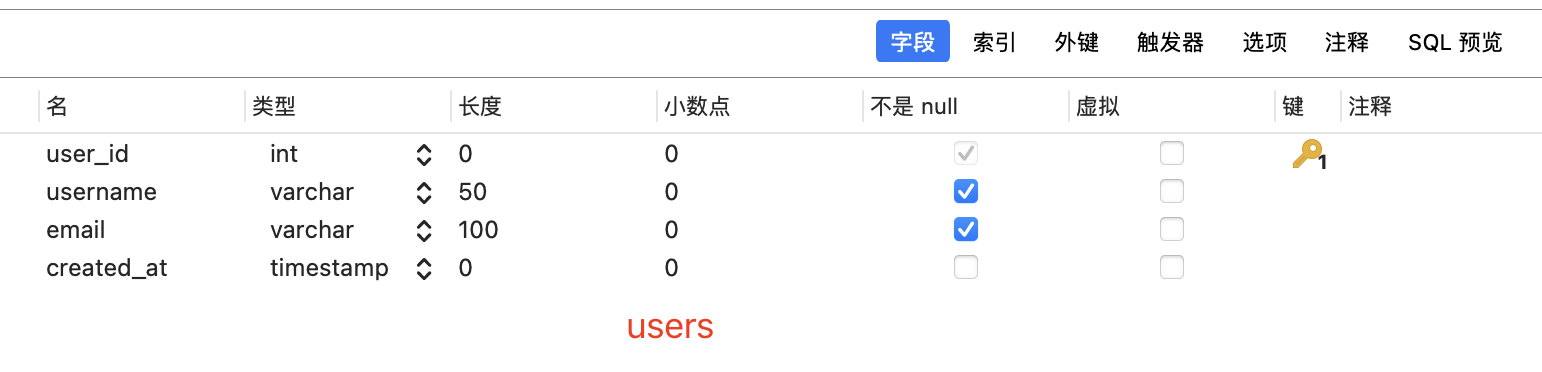
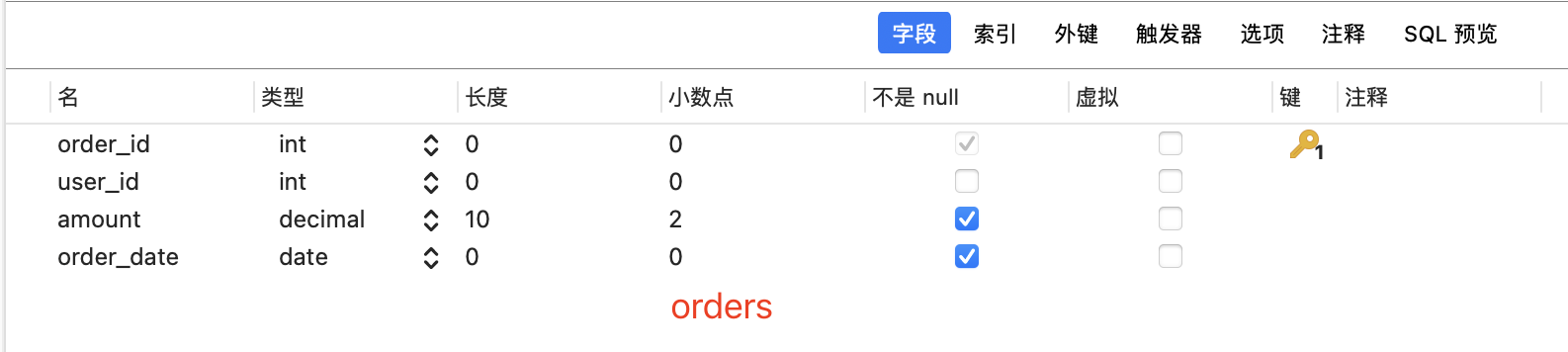
准备数据
SELECT count(*) FROM users; # 1896
SELECT count(*) FROM orders; # 15245293
联表查询
先执行两个查询,大表驱动小表和小表驱动大表,检查一下两者的差异。
SELECT username,SUM(amount) FROM users AS a LEFT JOIN orders AS b ON a.user_id = b.user_id GROUP BY username
查询时间:36.55
SELECT username,SUM(amount) FROM users AS a RIGHT JOIN orders AS b ON a.user_id = b.user_id GROUP BY username
查询时间:42.75
这里的主要问题是大表驱动小表会根据大表的数据量进行数据库连接,所以会额外消耗更多时间。
索引
复制上面表orders得到表orders_copy1创建索引如下

SELECT user_id,SUM(amount) FROM orders GROUP BY user_id;
查询时间:4.68
SELECT user_id,SUM(amount) FROM orders_copy1 GROUP BY user_id;
查询时间:506.1
这里是一个错误示范,同样的sql查询时间相差了100倍。使用EXPLAIN检查一下


关于explain相关的解释在文末
可以看到这里我们使用了索引user_id,但是为什么使用索引的情况下会导致查询效率低这么多,原因是因为这里索引创建有问题。type=index 表示MySQL通过索引扫描来满足查询,但如果需要返回的列不在索引覆盖的范围内,MySQL可能会进行额外的回表操作(从主表获取数据)。这种情况下,虽然使用了索引,但查询效率可能会变低。
我们重新创建索引,执行sql检查

SELECT user_id,SUM(amount) FROM orders_copy1 GROUP BY user_id;
查询时间:2.16
验证成功,这里顺便讲一下联合索引的最左原则,例如索引idx_col1_col2_col3,在sql中使用col1,col2等都会使用到索引,但是col1+col3,这种跳过col2字段就无法使用索引。
联表使用索引
SELECT username,SUM(amount) FROM users AS a LEFT JOIN orders AS b ON a.user_id=b.user_id GROUP BY username;
查询时间:37.64
SELECT username,SUM(amount) FROM users AS a LEFT JOIN orders_copy1 AS b ON a.user_id=b.user_id GROUP BY username;
查询时间:33.07
联表查询以后发现慢了很多,使用EXPLAIN检查一下

 加上索引以后重新查询
加上索引以后重新查询
SELECT username,SUM(amount) FROM users AS a LEFT JOIN orders_copy1 AS b ON a.user_id=b.user_id GROUP BY username;
查询时间:2.809
explain各列释义
id:选择标识符
select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示索引类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
type的索引类型
system
只有一条数据的系统表或衍生表只能有一条数据的主查询
const
仅仅能查出一条的SQL语句并且用于Primary key 或 unique索引;
例如:SELECT * from shop s where s.id=?
eq_ref
唯一性索引:对于每个索引键的查询,返回匹配唯一行数据(有且只有1个,不能多,不能0)
ref
非唯一性索引:对于每个索引键的查询,返回匹配的所有行(可以是0,或多个)
range
检索指定范围的行,查找一个范围内的数据,where后面是一个范围查询 (between,in,> < >=),
in 有时 有可能会失效,导致为ALL ,例如索引类型不是b+,而是hash,hash索引速度更快,但并不支持范围查询
index
把索引的数据全查出来
ALL
全表扫描
效率排序:system>const>eq_ref>ref>range>index>ALL